THREADBLOCK-SWIZZLE (GROUP-M, GROUP-N)
下面这张图可以直观地解释 threadblock-swizzle 想要优化的方向。假设一共有 6 个 Compute Unit;左图是 raster along M 同时 swizzle=1,右图是 raster along M 同时 swizzle=2。 看左图,出一波 6 个输出块需要加载 7 个输入块(6A + 1B);而右图,同样出一波 6 个输出块只需要加载 5 个输入快(3A + 2B)。如果不考虑 cache hit 的话,显然右侧对带宽的需求更低,性能更好。 这个也好理解,小学就学过,当面积相等的时候,正方形的周长最短,所以越接近方形的分组,需要加载的输入就越少。
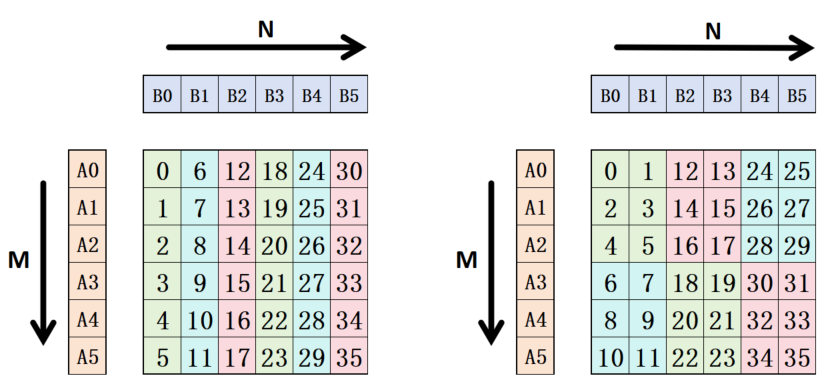
不过在实际情况下,需要考虑 CU 的个数,L2 缓存的大小等因素,很难从第一性原理出发计算出最好的 raster 方向和 swizzle_size,一般是作为参数去 autoune。 比方说假设共有 6 个 CU,那么基本可以按照右图的顺序计算 tiles:第一波先计算 0-5,第二波计算 6-11,以此类推;但是如果有 12 个 CU,那么第一波此就可以计算 0-11,左图和右图就没有区别了。在这种情况下,我们会希望 CU/swizzle_size < M tiles,这样不同组的 tiles 确实会在不同的波次中计算。
PERSISTENT-KERNEL
Persistent kernel 指的是每一个 cu 只起一个 threadblock, 这个 tg 一直执行同一个 kernel。比方说共有 4 个 cu,那么共起 4 个 tg,每个 cu 一个单独的 tg。
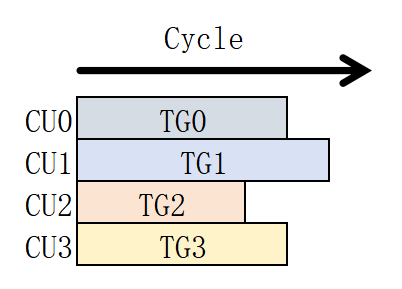
Persistent kernel 的好处有两点:
- 可以特化 cu,比方说让 cu0-cu2 执行 moe kernel,而 cu3 进行卡间通信,这样可以避免通信操作打乱 moe kernel 的流水;
- 通过给每个 kernel 分配相同的计算量,可以大概控制所有的 cu 都在差不多同一时刻完成,避免出现 idle 的状态,streamk 就是这样的一个例子;
- 可以最大化重复利用同一个 tg 内的 SMEM 和寄存器中的数据;
- 减少下发 tg 带来的额外的开销;
但是也有一个坏处,因为每个 cu 只有一个 tg 占用,相当于 occupancy 是最低的,十分不利于 simd 通过交换 warps 来隐藏延迟; 不过在 warp-specialize 的情况下,即使是同一个 tg 内,不同 warp 执行的指令流也不相同,通过交换 warps 还是可以实现隐藏延迟的效果。
值得一提的是,在 streamk 的论文中,为了将 k iterations 平均分配给每个 cu,作者实现了 persistent kernel;但是我认为这是无意为之, 或者说是 streamk 导致的自然结果,而不是目的。完全是可以通过 non-persistent 的方式实现 streamk 的。