原理
StreamK 这个算法的目的是将 GEMM 中的 K 方向的 MAC 均分到每一个 Compute Unit,使得所有 CU 可以同时结束,从而减少 idle 的时间。
GEMM 最常见的调度算法是每一个输出的块由一个 TG 负责计算,这个 TG 把 K 方向的累加全部算完了。这个算法以前是没有什么问题的,性能很好。但是现在 CU 性能越来越强大,就使得切块约切越大,对于同一个 MKN,需要用到的 TG 越来越少;而同时 CU 数量越来越多,这就使得很多情况下,CU 没有被打满,浪费了算力。
当然可以减少切块的大小,但是这样会使得 cache 的利用率降低。也有一种 split-k 的算法,将一个输出的块平均分给 N 个 TG 来计算,最后再累加到一起。Split-k 的切分是通过在 K 方向均匀地切分,每个 TG 计算相等的一部分的 K 方向的 MAC。这个算法提高了 CU 的利用率,但是不能完全消灭 CU 的 idle 的时间。Stream-k 的算法就是进阶版的 split-k,K 方向不进行均匀切分,而是按需分配,相切多少切多少,满足的目标就是所有 CU 分配到的 K 方向的 MAC 是完全相等的,这样就完全没有 idle 的浪费。
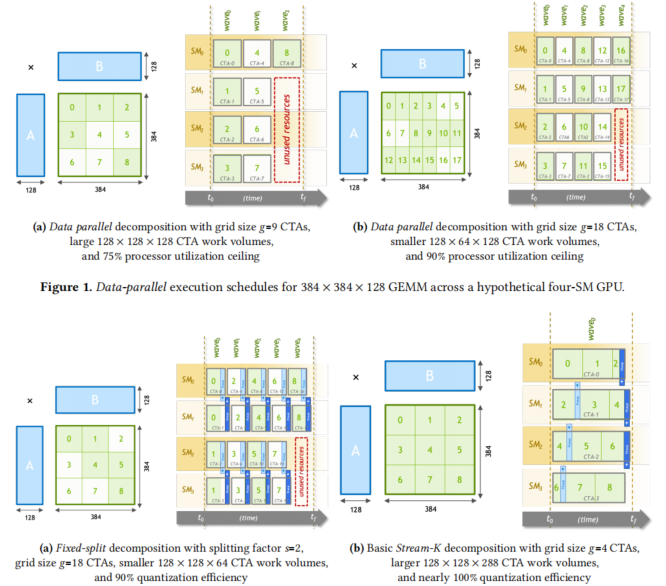
Xprof 显示 80 个 CU 的耗时基本是平均的。
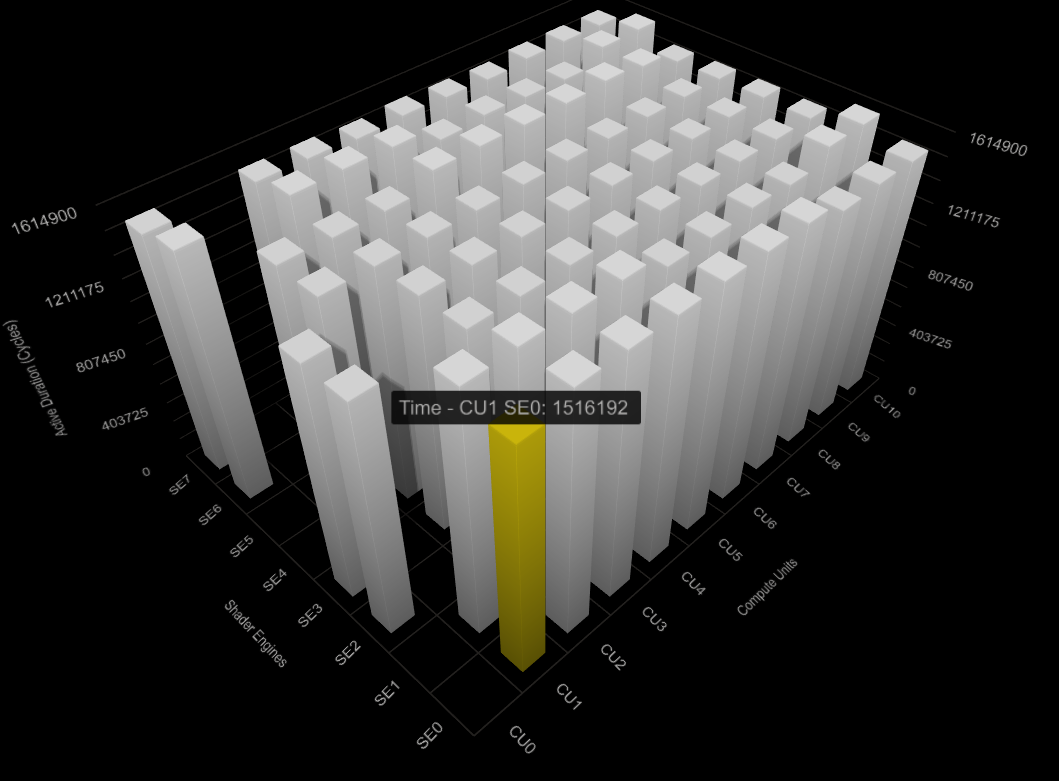
下图是 120CU 上 SplitK 的,可以看到非常不均匀:
问题和改进
Streamk 存在一个很大的问题:当输出的块的数量不能被 CU 数量整除的时候,同一时间切片下,不同的 CU 可能在处理不同 K 方向位移的输入数据,这就使得 L2-Cache Hit Rate 会明显下降,从而影响到整体的性能。
为了减轻这个副作用,streamk 的作者提出了另外两种改进:1. 仅将最后一个不完整的波次进行 streamk,之前的波次还是使用 data-parallel,这样既保证了一定的 L2-Cache Hit Rate,又保证了各个 CU 分配到的任务是均等的;2. 前一种改进还存在一个问题,就是 CU 间的同步带来了额外的 idle,所以作者提出将最开始的两个波次做 streamk,后面的波次用 data-parallel,这样既保证了一定的 L2-Cache Hit Rate,也可以用后面波次来掩盖 streamk 带来的 CU 之间的同步的开销。
w4a16 awq_gemm 上的试验
因为目前在 BMZ 上,我们暂时没有 CU 间同步的指令,所以我只测试了前两种实现。K 方向的 reduce-sum 是通过第二个 kernel 来实现的,这个 kernel 的时间也统计到整体的性能中。对于第一种实现方式,测试下来性能下降很多,表征了一下确实是 L2-Cache Hit Rate 很低,这里就不再赘述。第二种实现方式,即 Data-Parallel + 1 Streamk,我在四千多个 gemm 的 MNK 组合上进行了 autotune,筛选出最好的 BLOCK_SIZE 和其他超参数,相比于原来的 SplitK 算法,性能的提升和下降通过下图可以看出来:
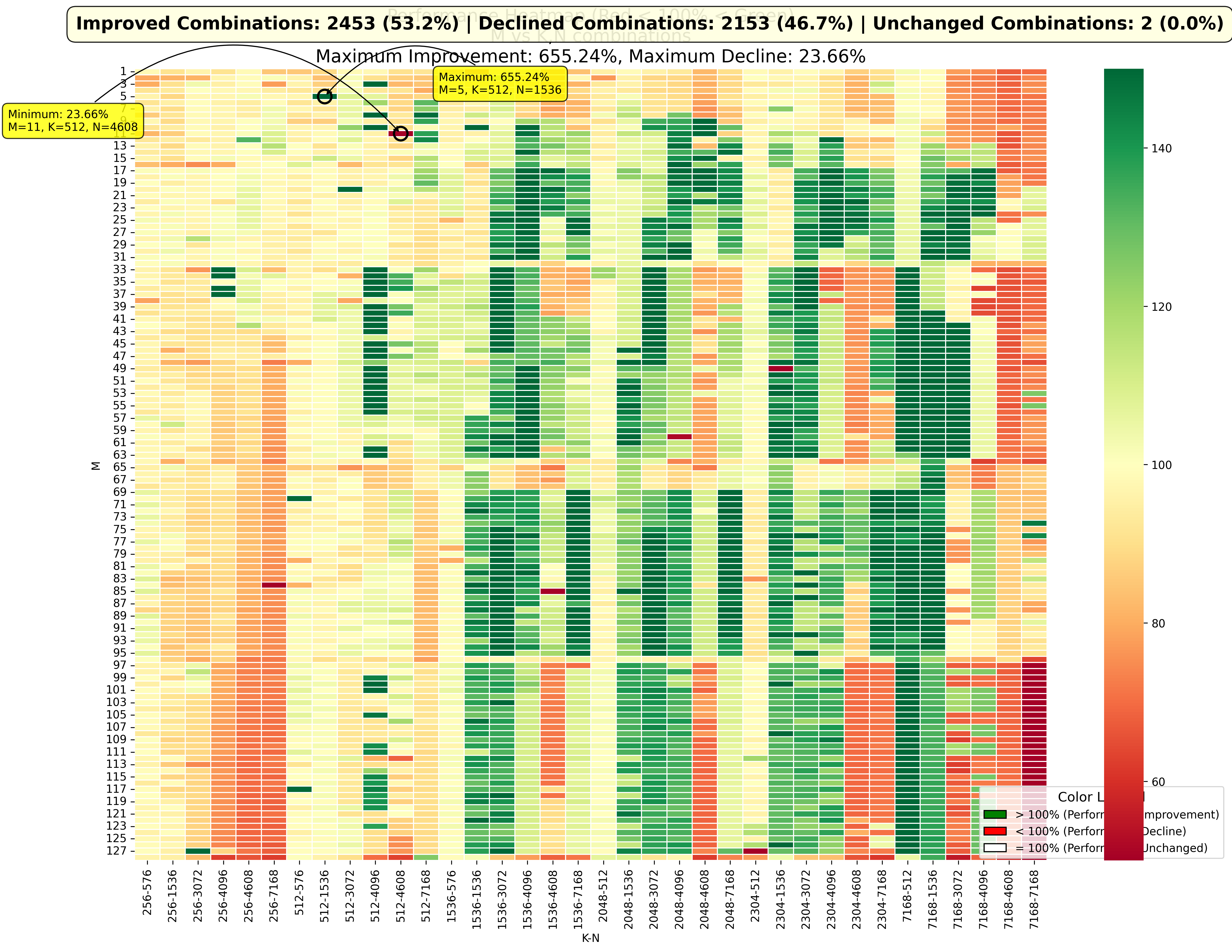
横坐标是 K-N 组合,纵坐标是 M,绿色表示性能提升,红色表示性能下降。有超出一半的组合性能是提升的,提升最多的大概是原来的 6 倍;不到一半是下降的,最差的大概是原来性能的 1/5。对于提升在 2% 以上的所有的组个(大概有48%),平均提升大概是 31 个百分点。对于有些极端的组合,性能提升巨大,猜测可能是因为原来正好多出来少量的 TG 占用了一个波次,使得绝大部分的 CU 都处在 idle 状态,而 streamk 恰好解决了这个问题。
因为 DCU 上暂时没有 CU 间同步的指令,因此使用了第二个 kernel 来做 reduce-sum,这带来一个问题,就是第一个 gemm kernel 需要申请一个比较大的显存空间来存放结果,因为 streamk 的特性,这个显存空间会比 data-parallel 或者 splitk 大很多。如果 gemm 采用 data-parallel 的方式,结果大小是 (M, N),而 streamk 把每个输出块均分到了所有 CU 上,所以结果是 (S, M, N)。这里的 S 代表输出块最多会被分配到多少个 CU 上,最差情况下,可能最后一个波次只有一个 TG,那么它将被均分到所有的 CU 上(比方说 120 个 CU),那么将需要申请 (120, M, N)这么大的显存空间,初始化为零,然后再在上面进行 reduce-sum,这个开销是很大的。这是目前硬件的限制(后面可以尝试用 automic add 来替代第二个 reduce kernel)。
StreamK++
Streamk 的作者觉得还不过瘾,提出了升级版本,其本质上是调整 streamk 的波次的比例。从完全没有 streamk (全部是 data-parallel),到最多将最后七个波次使用 streamk,一共八种方式,进行调优。
我也在 w4a16 awq_gemm 上测试了,然而结果并不理想。Autotuning 没有选择大于 1 个波次来做 streamk,全部选择了不做 streamk,或者仅有最后一个波次做 streamk(也就是 data-parallel + 1streamk 的方式)。对所有选出的配置进行了一下统计,发现在 data-parallel 下,绝大多数的 MKN 组合仅仅只有 1-2 个波次 (每个波次 80 CU),较少的会有 4 个波次,仅有极少的会有 12 个波次。这也是可以理解,triton 尽量选择 BLOCK_SIZE 较大的配置,这样可以使得 cache 的利用率较高,结果就是 TG 数量的减少,也就是波次的减少。在波次比较少的情况下,streamk 带来的 L2-Cache Hit Rate 降低的副作用会比较明显,通过下面的案例可以看出来。
StreamK++ 案例分析
M = 128, K = 7168, N = 4096
在 80cu 的 BMZ 上,autotuning 选出的最好的配置是(耗时 0.1934 ms):
{
"BLOCK_SIZE_M": 64,
"BLOCK_SIZE_N": 32,
"BLOCK_SIZE_K": 64,
"STREAMK_BATCH": 1,
"num_warps": 4,
"num_ctas": 1,
"num_stages": 1,
"maxnreg": None,
"waves_per_eu": 1
}
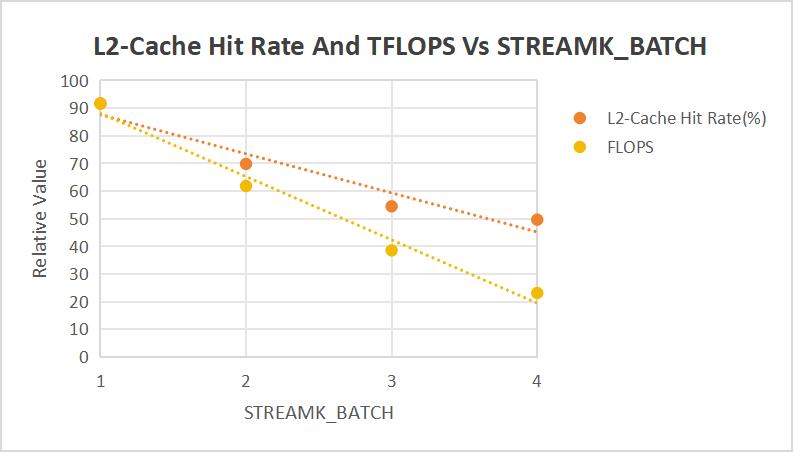
如果是 data parallel,这个配置共产生 256 个 TG,所以是 3 个完整的 80cu 的波次加上一个不完整的 16cu 的波次。STREAMK_BATCH=1 正好是将最后一个不完整的在所有 cu 上做了平均。我逐一表征了 STREAMK_BATCH 从 1 到 4,发现 L2-Cache Hit Rate 单调下降,这个正是 streamk 的第一大副作用,怪不得只选中了 STREAMK_BATCH=1 的配置。从下图中也可以看到,FLOPS 和 L2-Cache Hit Rate 的相关性很高,推测当 STREAMK_BATCH 增加时导致的性能下降主要来自于 Cache Hit Rate 的下降。
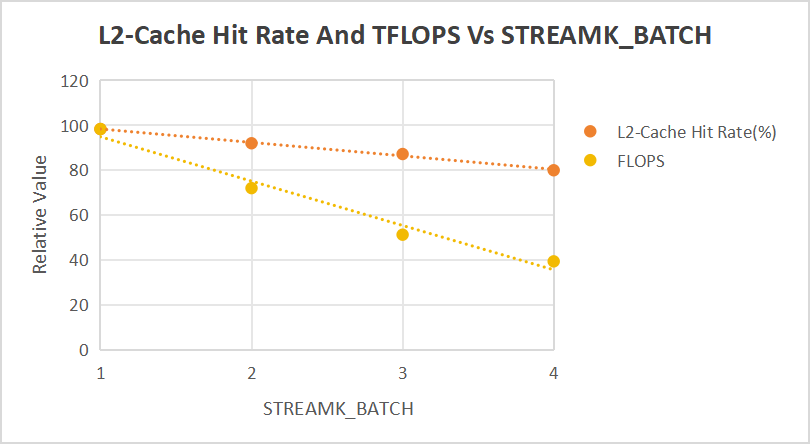
手动把配置改成下面这样,减小 BLOCK_SIZE,增加 TG 数量。在这个配置下,如果是 data parallel,共有 2048 个 TG,是 25 个完整的波次加上最后一个 48cu 的波次。STREAMK_BATCH=1 正好是将最后一个不完整的波次在所有的 cu 上进行了平均。
{
"BLOCK_SIZE_M": 16,
"BLOCK_SIZE_N": 16,
"BLOCK_SIZE_K": 16,
"STREAMK_BATCH": 1,
"num_warps": 1,
"num_ctas": 1,
"num_stages": 1,
"maxnreg": None,
"waves_per_eu": 1
}
这个 data parallel 的波次比较多(25个波次),把 STREAMK_BATCH 从 0 调到 4,L2-Cache Hit Rate 的下降幅度就没有那么明显了。
总结
Streamk 解决了 CU 负载不均衡的问题,对于多数的 gemm size 有性能上的提升,对于 CU 极端不平衡的场景,有极大的性能提升。不过 streamk 导致 L2-Cache Hit Rate 下降的副作用也比较明显。在 w4a16 awq_gemm 上测试的结果表明 data-parallel + 1streamk 的策略是比较均衡的。Streamk++ 没有什么作用。后续需要测试一下 automic-add 和 streamk 的结合使用。