实验数据
性能的总体影响
由于之前的 streamk 的实现,导致了约一半的 GEMM MNK 组合出现了性能的下降;因此,我把 data-parallel,splitk 和 streamk (dp + 1 streamk 的版本) 都加入了 triton 的 autoune 的范围。在四千多个 MNK GEMM 组合上进行了测试,结果如下:
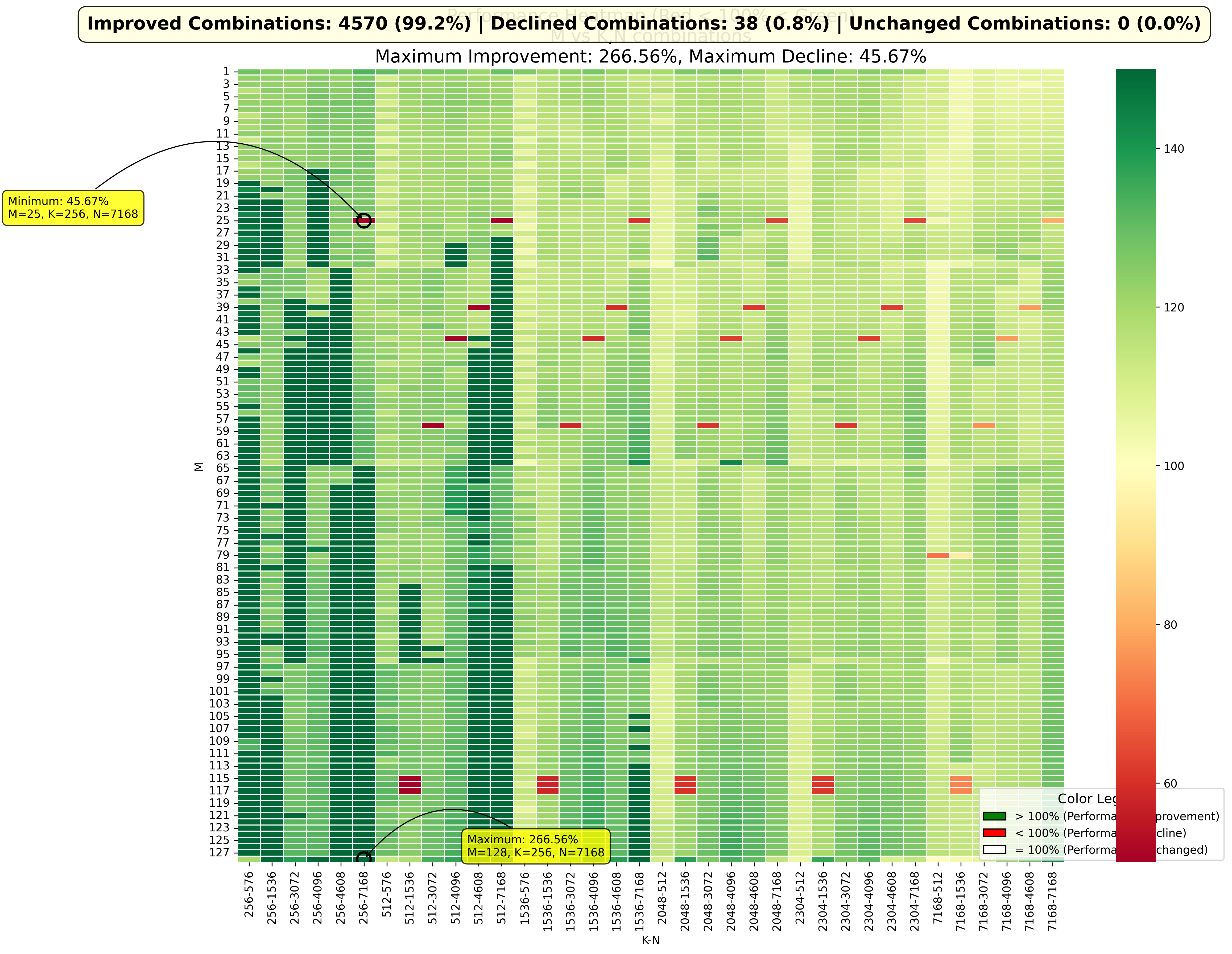
可以看到 99.2% 的组合都是性能提升的,也出现了一些性能下降的。这里需要强调一下,这次的测试除了引入 streamk 之外,也做了一些数据精度上的调整。之前的 GEMM 在 K 方向的累加是用 float16 实现的,这个跟甲方确认过没有问题。但是在实现 streamk 的过程中,因为 k 方向的累加次数可能会很多,另外也是为了使得 GEMM 的精度更高,因此统一都更换到了 float32 进行累加,这个改动会使得性能下降很多(大概比 float16 精度下降约一半)。因此这里的性能的改变并不是单单由于 streamk 导致的,实际上如果单独考量的话,streamk 的提升肯定会更多。
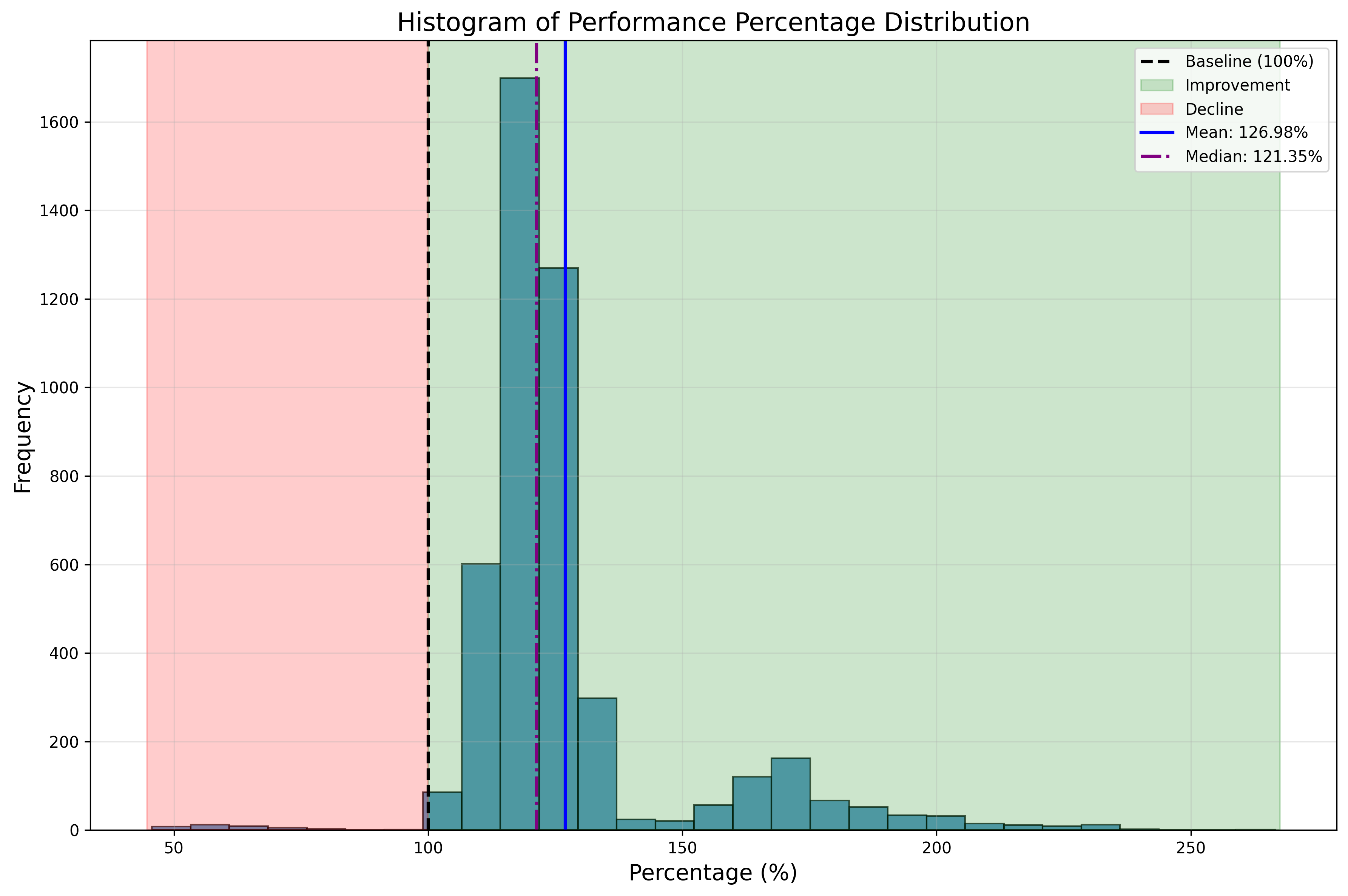
下面这个分布图可以直观地看出来性能提升的分布,可以看到平均数和中位数都大约是 120%-130%,另外在 150%-200% 之间也有分布。最多的提升到原来的 266%,而最差的是原来性能的 46% (因为累加精度的提升)。
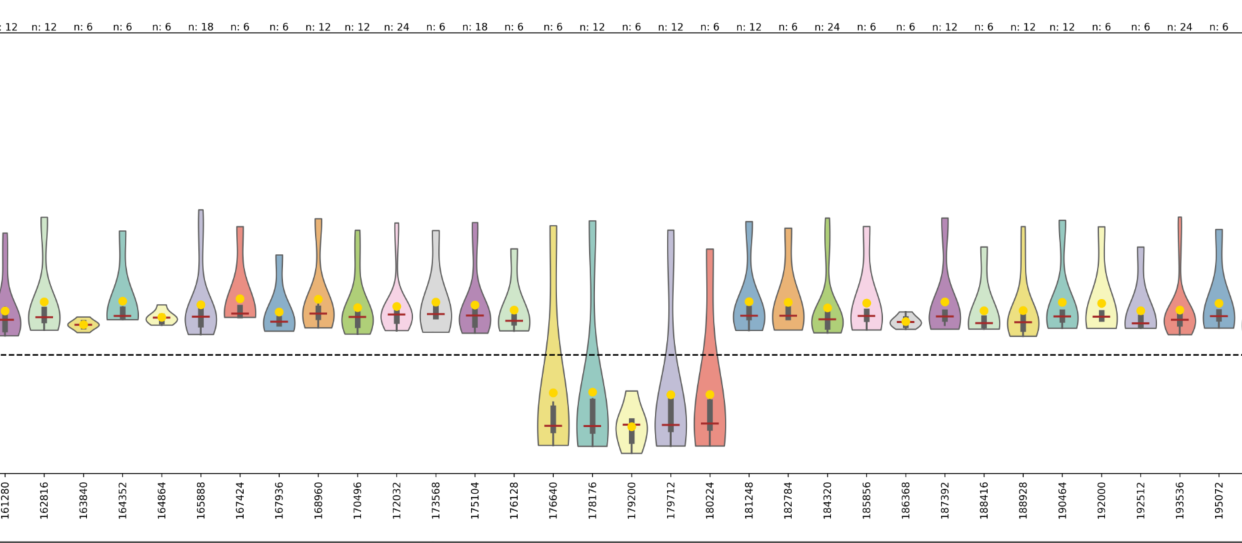
性能下降的奇怪 pattern
在第一张图中,注意到一个奇怪的现象,性能下降的 MNK 似乎遵循某种 pattern,排列得非常有规律。下图很明显地体现出来,当 M * N 等于三个数的时候,性能是有较多下降的。这张图中横坐标是 M * N, 纵坐标是性能百分比,虚线表示 100% 的位置。至于原因,我研究了半天也没有发现为什么,怀疑可能跟用 atomic_add 写出 float32 的结果矩阵有关系,但是没有完全解释清楚。
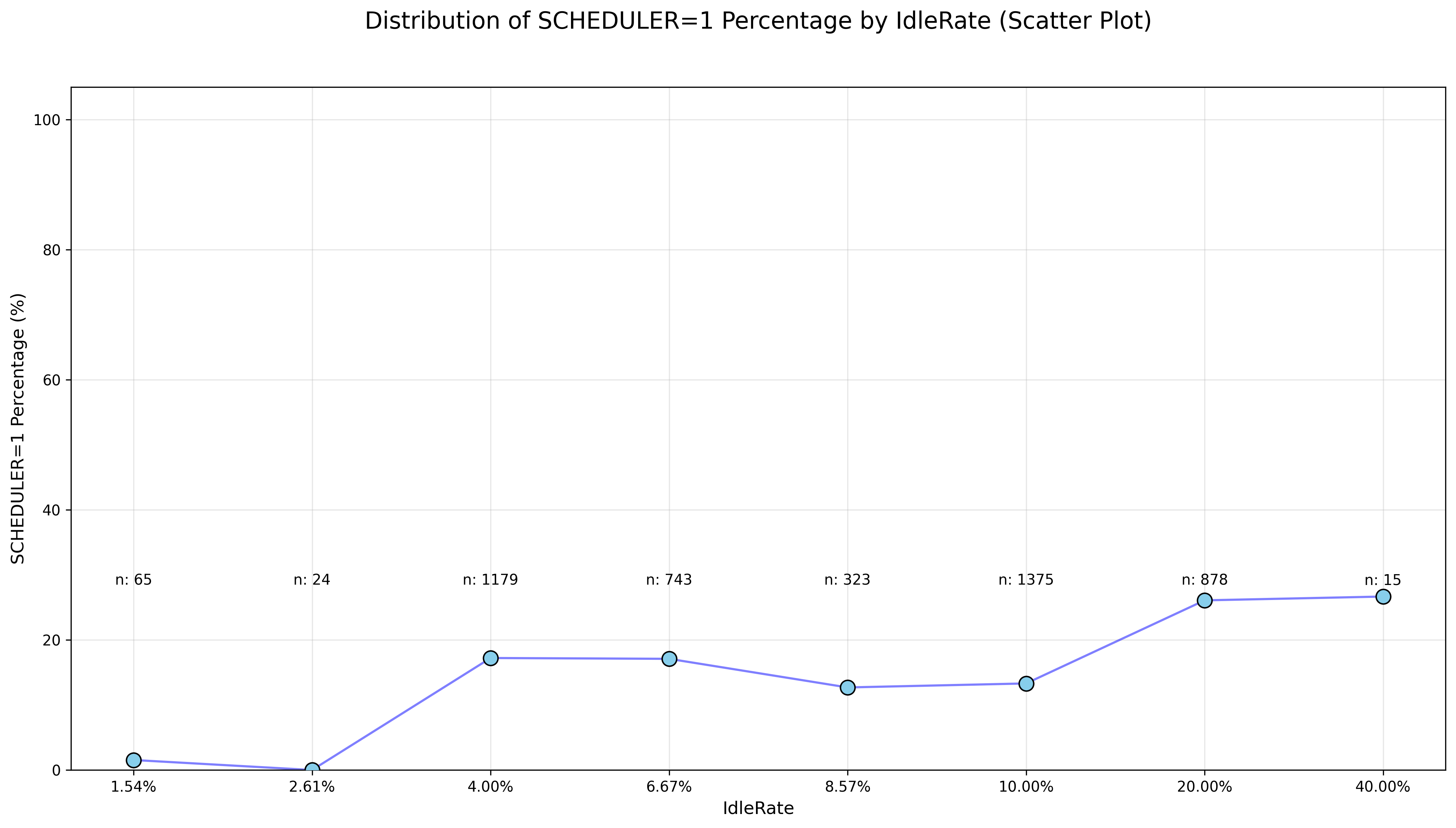
性能与 Idle 的关系
我计算了一下在 streamk 之前的 block 的切分策略,导致的 Compute Unit Idle 的百分比,以此为横坐标;纵坐标是将 streamk 引入 autotune 范围后,同一组最终选择 streamk 调度策略的百分比。可以看到,基本上来说,原来的 IdleRate 越大的,越有可能选择 streamk 的调度策略。这个也是符合猜想的。
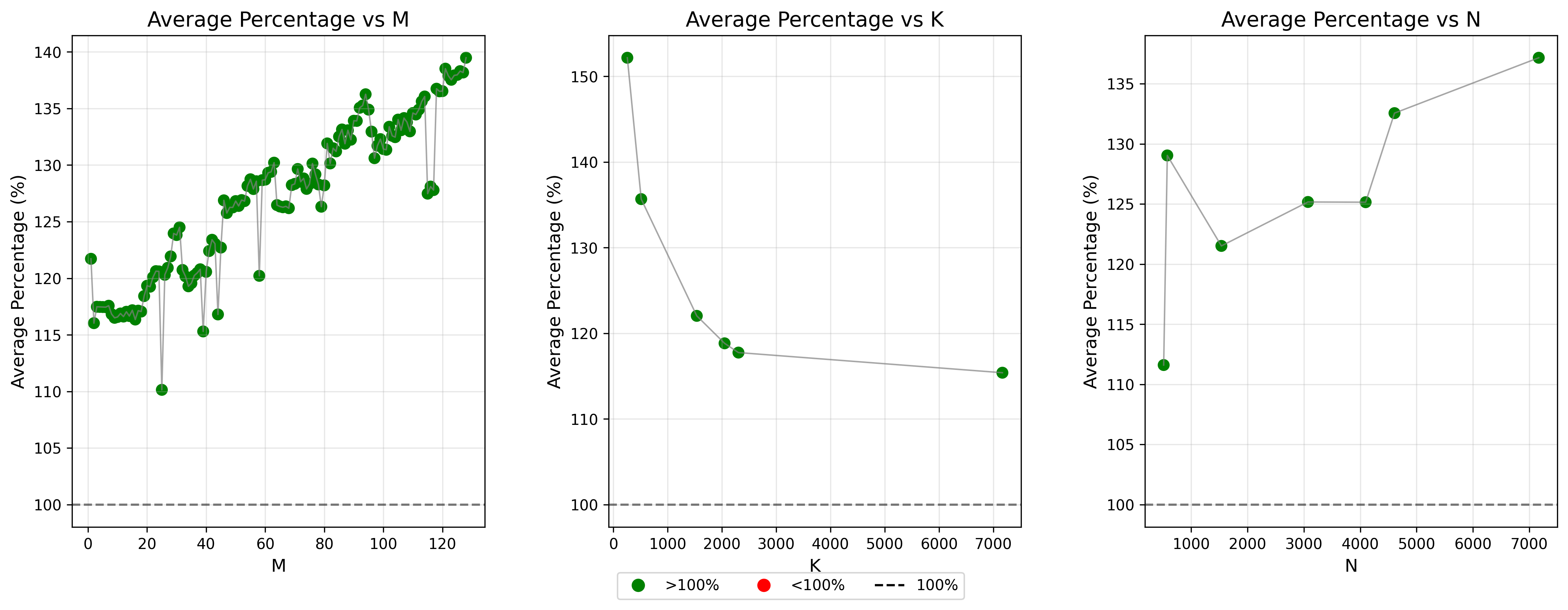
性能与 MNK 的关系
下图展现了性能提升和 MNK 各自的关系,基本上可以总结为 M 和 N 与 streamk 成正相关,K 与 streamk 成负相关。 GEMM 的 MAC 总数是 2 * M * N * K,内存搬运量是 M * K + N * K + M * N,总的来说,M 和 N 越大,计算/带宽占比就越大,对于 streamk 这种优先把 CU 打满的策略来说更友好。而如果 K 越大,本来 splitk 切分出来的 block 越多,本身的 IdleRate 可能就越小,所以 streamk 带来的性能提升越小。以上是我的定性的猜测。